Kubernetes Network Policy APIs
This post explores multiple ways network policy can be expressed in Kubernetes. This includes the native API and CNI-plugin specific Custom Resource Definitions (CRD). By understanding these different approaches, you will be able to make an informed decision around what is best for your environment!
Enforcing network policy in a Kubernetes cluster is a common pattern. By
enforcing rules with the same technology facilitating the pod network, you can
achieve granular levels of segmentation. It also enables you to use constructs
familiar to Kubernetes. For example, allowing traffic based on
labels.
Kubernetes provides
NetworkPolicy
as a first class API. If you have a Container Networking Interface (CNI) plugin
that supports it, these rules are enforced. However, the standard Kubernetes
NetworkPolicy API can be limiting. This is why providers such as
Calico and Cilium offer
their own network policy CRDs.
Kubernetes NetworkPolicy
NetworkPolicy objects can be added to any Kubernetes cluster. In order for
these policies to be enforced, your cluster must run a CNI plugin that respects
these policies. Common CNI plugins with this support are as follows.
By default, Kubernetes clusters do not restrict traffic. Pods can communicate with any other pods. External clients can also communicate with pods, assuming they have a way to route to the cluster's virtual IPs (VIP).
NetworkPolicy is namespace scoped. Rules defined in the policy allow traffic
and are combined additively. This raises the following question. If Kubernetes
allows all traffic and added rules are only for allowing traffic, how would you
restrict traffic?
When a NetworkPolicy object is introduced to a namespace, all traffic not
explicitly allowed becomes denied. This new implicit deny-all (minus what rules
you created) applies to everything satisfying the spec.podSelector. This
behavioral change trips up many newcomers of NetworkPolicy.
A namespace-wide policy can be created by setting the podSelector value to
{}.
Consider the following manifest that allows pod-a to receive traffic from
pod-b and egress to it. It is a namespace-wide policy due to the
spec.podSelector.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: team-netpol
namespace: org-1
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
ingress:
# allow all inbound traffic on port 80
- from:
ports:
- protocol: TCP
port: 80
egress:
# allow DNS traffic
- to:
ports:
- protocol: UDP
port: 53
- to:
- namespaceSelector:
matchLabels:
name: org-2
- podSelector:
matchLabels:
app: team-b
ports:
- protocol: TCP
port: 80
Traffic is allowed from team-a to team-b. Traffic is also accepted by
team-a when trying to reach it on port 80.

The above demonstrates the impact this policy has on the cluster. Since team-a
accepts all ingress on port 80, team-b can egress to it. team-a is also
enabled to egress to team-b. However, should team-a want to reach
google.com, it will be blocked due to the fact that it is not explicitly
allowed. team-b on the other hand can reach google.com as there is no
NetworkPolicy present in the org-2 namespace.
Interestingly, if you were to move team-b into the same namespace as team-a,
team-b would no longer be able to send traffic to team-a.
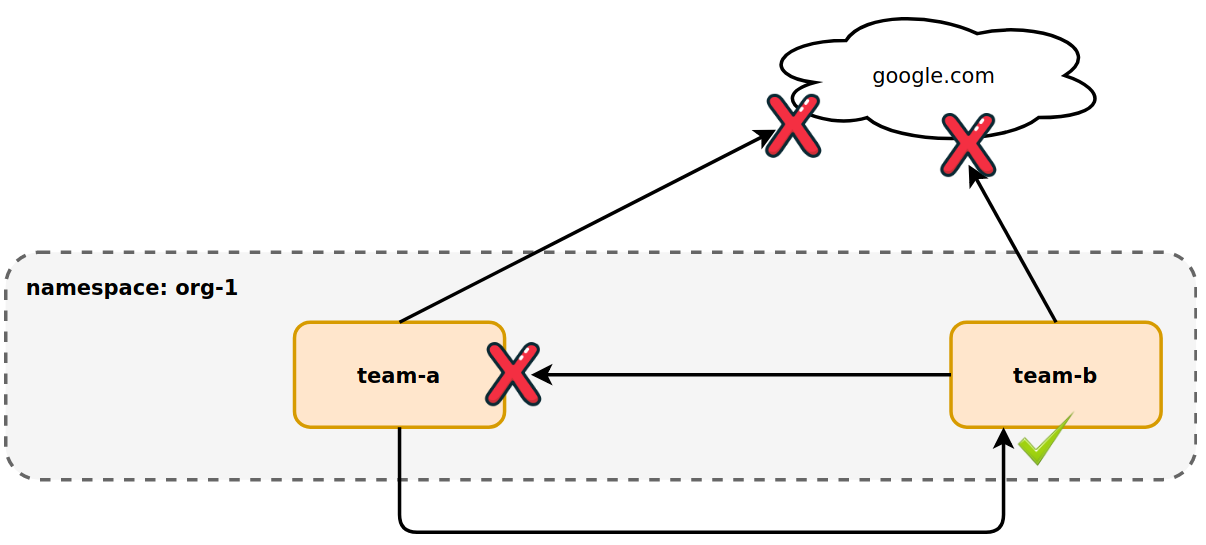
Now that team-b is part of the org-1 namespace, it is beholden to the
implicit deny brought on by the policy. It can no longer accept ingress and its
egress capabilities are limited to itself. These are the side-effects one should
expect when implementing namespace-wide policies (via spec.podSelecter: {}).
To limit the impact of a policy, the spec.podSelector can be set to team-a,
re-opening all ingress and egress traffic for pods without the label app: team-a.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: team-netpol
namespace: org-1
spec:
podSelector:
matchLabels:
app: team-a
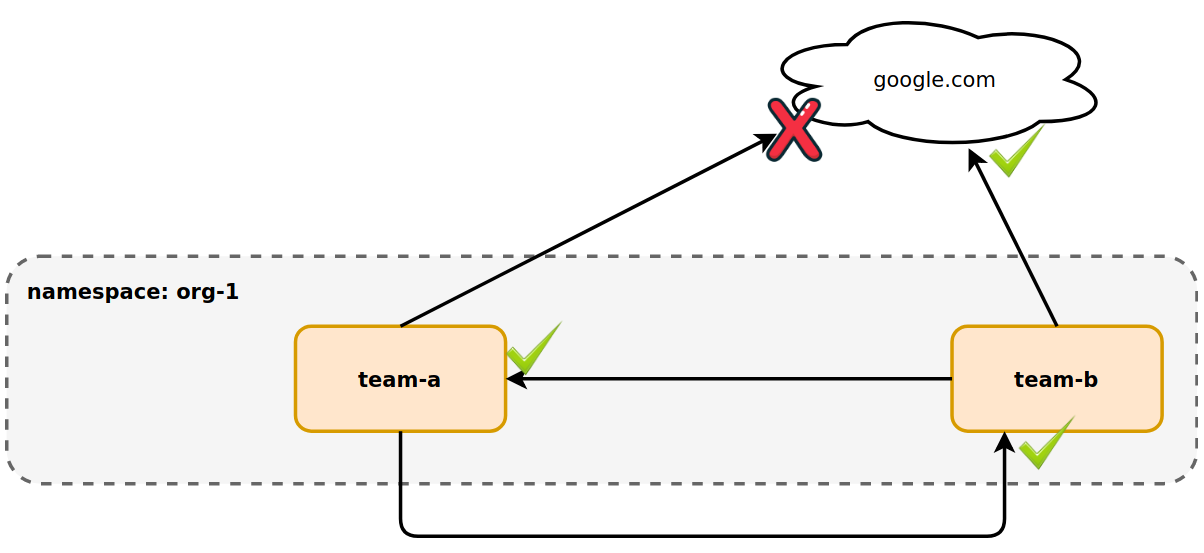
Now the implicit denial rules are scoped to team-a. team-b (and pods without
the label app: team-a) can accept ingress and create egress traffic freely.
As we have seen, there is flexibility to create workload-specific policies and namespace-wide policies. Your choice depends on the workloads and how you administer your namespaces. An example of a blanket policy that restricts all ingress traffic to pods in a namespace but does not restrict egress is as follows.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
namespace: org-1
spec:
podSelector: {}
policyTypes:
- Ingress
This is a common pattern that allows application teams to open ingress access as they see fit. Some clusters are setup to provision namespaces with an initial policy such as the above on namespace create. Achieving this requires extra engineering work.
NetworkPolicy has more features not highlighted here. Visit the
NetworkPolicy
documentation for examples.
Limitations
Over time, NetworkPolicy has become more feature rich. For example,
traditionally it only supported ingress rules. It also did not allow for
specifying IP CIDRs in rules. CNI plugins, such as Calico, have proven out these
capabilities and brought enhancements upstream. However, there are still
limitations you may care about.
A list of common limitations are as follows.
- No explicit deny rules.
- Lacking support for advanced expressions on selectors.
- No layer 7 rules.
- No limiting certain HTTP methods, paths, etc.
- No cluster-wide policy.
To address these limitations, CNI plugins such as Calico and Cilium offer their own network policy CRDs.
A limitation I have found most interesting is the lack of cluster-wide policy in the native API. This ask is rooted in a desire to achieve micro-segmentation across workloads via one source of truth (manifest). In the next section, you'll see an example of this and the Calico CRDs.
NetworkPolicy CRDs
Calico offers a NetworkPolicy CRD and a GlobalNetworkPolicy CRD. These CRDs
are applied using calicoctl. Depending on your Calico deployment, they are
written to kube-apiserver or an etcd. The NetworkPolicy CRD is namespace
scoped like the Kubernetes NetworkPolicy API. It includes a larger feature set
such as the deny rules, levels of rule resolution, L7 rules, and more. The
GlobalNetworkPolicy CRD is similar but is cluster-scoped. A rule applied in
this CRD impacts every pod that satisfies its selector(s).
The upcoming example applies a "default-deny-all" policy to the cluster. It will
make an exception for kube-system by allowing all traffic to any namespace
with the label name: kube-system. Namespaces do not have this label by
default. The following command will add it.
kubectl label namespaces kube-system name=kube-system
Assume you want to deny traffic for pods in non-system namespaces by default.
Teams can add their own namespace-scoped policies to allow routes. Achieving
"micro-segmentation". This is a great use case for GlobalNetworkPolicy.
Consider the following CRD.
# This GlobalNetworkPolicy uses Calico's CRD
# (https://docs.projectcalico.org/v3.5/reference/calicoctl/resources/globalnetworkpolicy)
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: global-deny-all
spec:
# order controls the precedence. Calico applies the policy with the lowest value first.
# Kubernetes NetworkPolicy does not support order. They are automatically converted to an order
# value of 1000 by Calico. Setting this value to 2000, provides flexibility for 999 additional
# GlobalNetworkPolicies to be added and ensures Kubernetes namespace-scoped policies always take
# precedence.
order: 2000
types:
- Ingress
- Egress
# egress network rules
egress:
# Allow all egress traffic from kube-system.
- action: Allow
destination: {}
source:
namespaceSelector: name == 'kube-system'
# Allow egress DNS traffic to any destination.
- action: Allow
protocol: UDP
destination:
nets:
- 0.0.0.0/0
ports:
- 53
# ingress network rules
ingress:
# Allow all ingress traffic for the kube-system namespace.
- action: Allow
destination:
namespaceSelector: name == 'kube-system'
source: {}
Applying the above policy can be applied as follows.
DATASTORE_TYPE=kubernetes \
KUBECONFIG=~/.kube/config
calicoctl apply -f global-deny-all.yaml
calicoctlis available for download on github.

As seen above, this would block all egress and ingress traffic in namespaces
outside of kube-system. With the exception of DNS traffic (UDP:53). This one
manifest has cluster-wide control. However, teams can still apply Kubernetes
NetworkPolicy on top of that to "poke holes" for their egress and ingress
needs. For example, if you wanted to open all egress traffic to pod-a in the
org-1 namespace, the following Kubernetes NetworkPolicy could be applied to
the org-1 namespace.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: team-netpol
namespace: org-1
spec:
podSelector:
matchLabels:
app: team-a
policyTypes:
- Egress
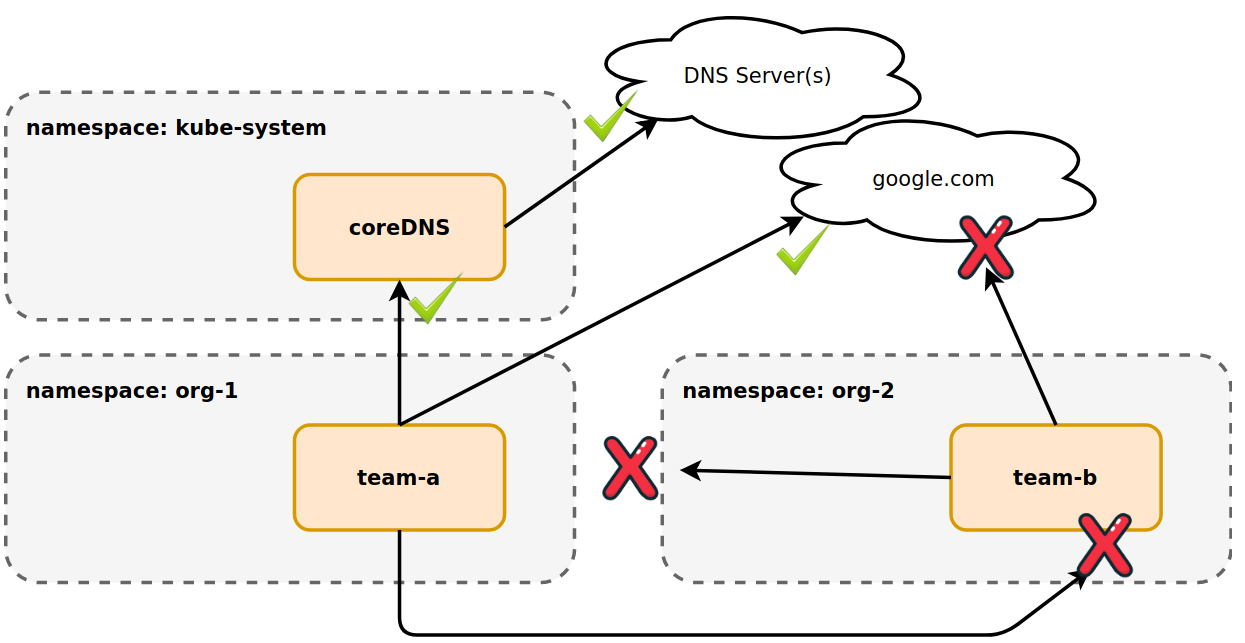
Now the team-a pod can egress to google.com. It can also egress to team-b,
but due to the GlobalNetworkPolicy, team-b is not accepting ingress traffic.
To resolve this, an allow rule for ingress would need to be added to the org-2
namespace.
This example can also be achieved if every team's namespace has a Kubernetes
NetworkPolicy that blocks all traffic by default. This does have trade-offs
though. Not only are those NetworkPolicy objects less flexible, you now have
N locations you need to update if you wish to change things about your
"default-deny" rule.
For more details on the CNI-plugin specific policies mentioned throughout this post, see the following links.
-
- applied via
kubectl - namespace scoped
- advanced rules and capabilities
- do not mix with standard k8s
NetworkPolicy
- applied via
-
- applied via
calicoctl - cluster scoped
- advanced rules and capabilities
- mix with standard k8s
NetworkPolicy
- applied via
-
- applied via
calicoctl - namespace scoped
- advanced rules and capabilities
- mix with standard k8s
NetworkPolicy
- applied via
Which Should I Use?
It depends. It could be both! The upside to using Kubernetes-native
NetworkPolicy is it is agnostic to your CNI plugin, making the definitions
portable across plugins. Policies defined in the cluster should act the same
in Weave, Cilium, Calico, and more. However, if some advanced features are
important to you, you may consider using a plugin-specific CRD. Should you
choose to change CNI plugins in the future, you may find yourself re-writing
network rules.
I personally see value in the global (cluster-wide) policies offered by Calico.
Thus I prefer to mix both CNI plugin-specific CRDs with Kubernetes-native
NetworkPolicy. For example, cluster administrators can create
GlobalNetworkPolicies defining a set of cluster-wide truths about how
networking works. Teams using the cluster create their own namespace-scoped
NetworkPolicy using the Kubernetes-native NetworkPolicy. Your ability to
take this approach depends on your CNI plugin. For example, Calico supports
mixing their CRDs and Kubernetes NetworkPolicy. However, Cilium recommends you
choose one or the other, based on their docs:
It is recommended to only use one of the above policy types [Kubernetes vs Cilium CRD] at a time to minimize unintended effects arising from the interaction between the policies.
Summary
I hope this post sheds light on the capabilities of the Kubernetes
NetworkPolicy API and enhancements available through CNI plugin-specific CRDs.
If you have questions, comments, or feedback, please reach me
@joshrosso.